
机器学习:第七篇 ChatGPT的实现之GPT网络的训练方式
虽然网络结构已经搭建好了,但是不同的模型所应用的训练方式也是不一样的,这里我们就来看看GPT网络的训练方式。
Word2Vec
嵌入(embedding)是机器学习中最迷人的想法之一。 如果你曾经使用Siri、Google Assistant、Alexa、Google翻译,甚至智能手机键盘进行下一词预测,那么你很有可能从这个已经成为自然语言处理模型核心的想法中受益。在过去的几十年中,嵌入技术用于神经网络模型已有相当大的发展。尤其是最近,其发展包括导致BERT和GPT2等尖端模型的语境化嵌入。 ——【大数据文摘出品】
我觉得这个图非常形象的描述了,word和vec的关系,最终我们的目的是将word转换成vec,这样就可以进行计算了。不过这并不是今天的重点,展开的话,太长了。
用向量和向量之间的关系来描述词与词之间的关系。
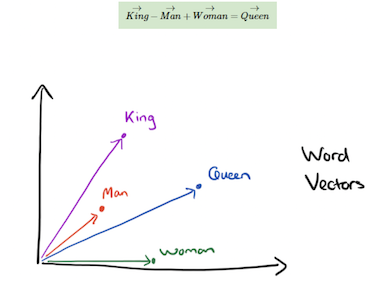
感兴趣的同学可以看看这个
所以数据集的处理流程一般就是两步:
1.分词器将文本分成一个个单词
2.将单词转换成向量
每个词向量通常有几百个维度(由自己指定,一般为256、512、768等),每个唯一的词在语料库的向量空间中有一个唯一的向量表示。
Positional Encoding
位置信息编码位于encoder和decoder的embedding之后,每个block之前。它非常重要,没有这部分模型就无法运行。Positional Encoding是transformer的特有机制,弥补了Attention机制无法捕捉sequence中token位置信息的缺点。
Positional Embedding的成分直接叠加于Embedding之上,使得每个token的位置信息和它的语义信息(embedding)充分融合,并被传递到后续所有经过复杂变换的序列表达中去。
使用Positional Encoding的优势
优势1
1.transformer中,模型输入encoder的每个token向量由两部分加和而成
- Position Encoding
- Input Embedding
2.transformer的特性使得输入encoder的向量之间完全平等(不存在RNN的recurrent结构),token的实际位置于位置信息编码唯一绑定。Positional Encoding的引入使得模型能够充分利用token在sequence中的位置信息。
优势2
论文中使用的Positional Encoding(PE)是正余弦函数,位置(pos)越小,波长越长,每一个位置对应的PE都是唯一的。同时作者也提到,之所以选用正余弦函数作为PE,是因为这可以使得模型学习到token之间的相对位置关系:因为对于任意的偏移量k,可以由的线性表示:
那么,在PyTorch中,我们可以这样实现
1 | import torch |
Mask
mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。其中,padding mask 在所有的 scaled dot-product attention 里面都需要用到,而 sequence mask 只有在 decoder 的 self-attention 里面用到。
Padding Mask
padding mask 用来对输入序列中的 padding token 进行 mask,使得模型不会在 padding token 上计算 attention。padding mask 的形状是 [batch_size, 1, 1, seq_len],其中 seq_len 是输入序列的长度。padding mask 的值是 0 或者 1,其中 0 表示该位置是 padding token,1 表示该位置是真实的 token。
Sequence Mask
sequence mask 用来对 decoder 的 self-attention 进行 mask,使得 decoder 在生成第 i 个 token 的时候只能 attend 到第 1 到第 i 个 token。sequence mask 的形状是 [1, 1, seq_len, seq_len],其中 seq_len 是输出序列的长度。sequence mask 的值是 0 或者 -1e9,其中 0 表示可以 attend,-1e9 表示不能 attend。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
1.对于 decoder 的 self-attention,里面使用到的 scaled dot-product attention,同时需要padding mask 和 sequence mask 作为 attn_mask,具体实现就是两个mask相加作为attn_mask。
2.其他情况,attn_mask 一律等于 padding mask。
那么,在PyTorch中,我们可以这样实现
1 | import torch |
Predict Next Token
GPT要做的任务是,预测接下来,会出现的token是什么,那GPT拿到这一笔训练资料的时候,选取BOS这个Token所对应的输出,作为Embedding的结果,用这个embedding去预测下一个应该出现的token是什么,一直预测下一个单词,直到预测到"
对于GPT使用,由于GPT的参数是Bert的4倍有余,使得去fine-turing一个模型需要更长,更大的训练时间。因此GPT提出了一个更加“疯狂”的使用方式,一种更接近于人类的使用方式。
没有进行梯度下降的"Few short leaning",也就GPT论文所提到的“In-context learning”
假设说我们需要模型做翻译,那么,我们会这样做:
1 | Translate English to Chinese: |
1.先给出问题的描述
2.再给出范例
3.最后给出问题,让模型去预测
而预测的结果,我们给出象棋
这就是One Shot Learning,还有Zero Shot Learning,这两种学习方式,都是在没有进行梯度下降的情况下,让模型去学习。
总结:就是在输入的时候,先让模型看一眼范例,然后让他根据范例进行输出。
总结
实际上的GPT网络是非常庞大的,而且OpenAI还有自己独特的训练方式,包括标注数据集等等,但是由于篇幅的原因,这里就不再一一介绍了。那么按照惯例,下一篇就应该手动实现一个简单的GPT模型了,敬请期待。

